Introduction
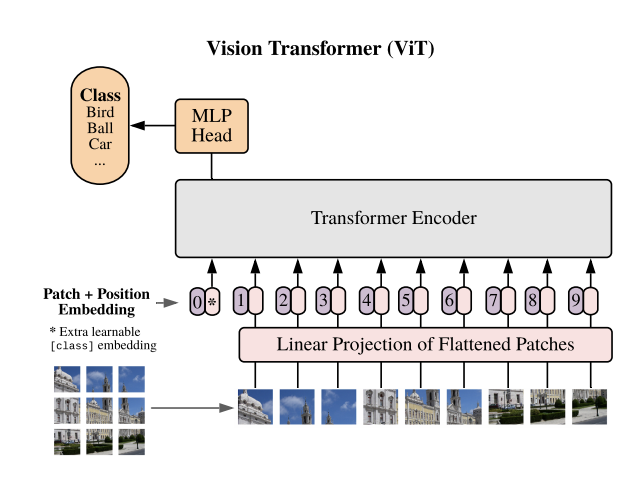
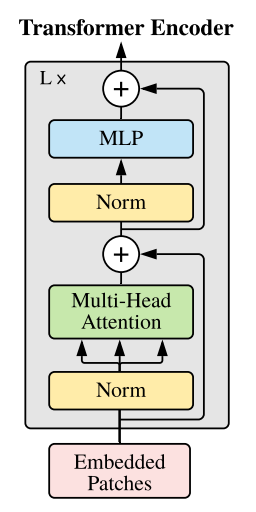
The reserach paper, "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale", introduced a Vision Transformer into computer vision, delivering state-of-the-art performance without relying on convolutional neural networks (CNNs). This innovation draws inspiration from the highly regarded Transformer architecture in natural language processing domain, where Transformers have outperformed CNNs. The goal of the project is to implement the paper and grasp the essential concepts in the Vision Transformer. We constructed the Vision Transformer (ViT) from scratch using PyTorch, conducted training with augmented data, and subsequently applied the model to perform image classification to identify dog breeds.
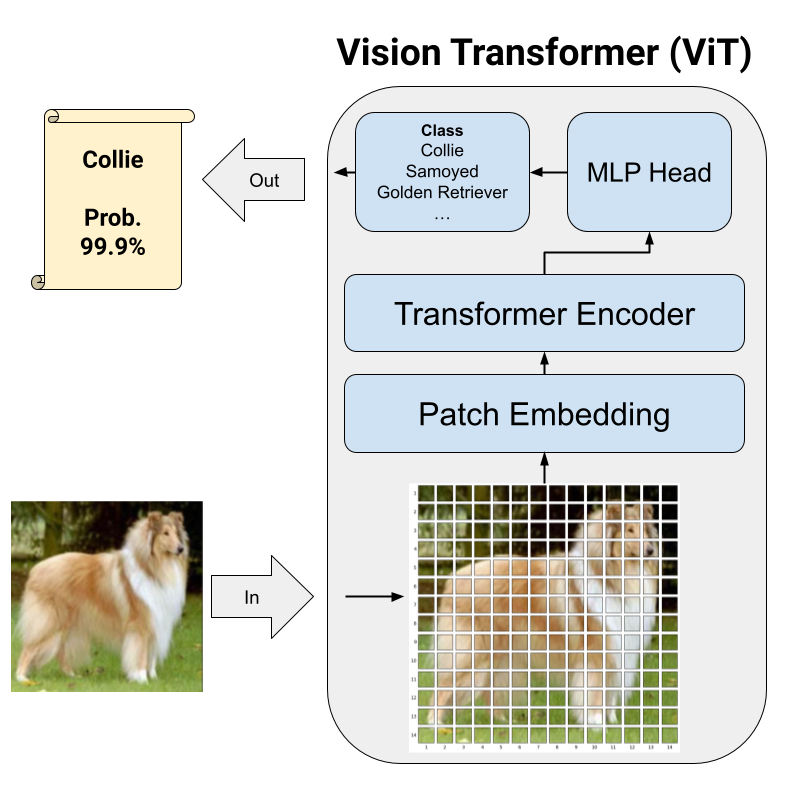
The figure below displays our project pipeline.